Компания Veeam Software на днях объявила о выпуске второй версии бесплатного продукта Veeam Business View 2.0. Мы уже писали об этом продукте - он представляет собой плагин для нескольких продуктов Veeam (например Veeam Backup and Replication и Veeam Monitor), с помощью которого можно разбить объекты виртуальной инфраструктуры не так, как нам показывает VMware, а своим собственным образом (например, на основе бизнес-единиц предприятия). Но при этом, это отдельный бесплатный продукт, развертываемый и настраиваемый отдельно.
Veeam Business View 2.0 расширяет возможности организации объектов виртуальной инфраструктуры. Теперь можно создавать представления хостов VMware ESX, кластеров HA/DRS и хранилищ (datastores). При этом создаваемые группы являются динамическими.
Например, вы определяете выражение для категоризации виртуальных машин по числу виртуальных процессоров - 1 vCPU, 2 vCPU, 4 vCPU. Затем Veeam Business View создает группы в соответствии с определенными правилами именования объектов и помещает туда представление виртуальных машин по группам для разных продуктов (например, Veeam Monitor или Reporter).
Еще пример - вы определяете граничные значения заполненности для своих хранилищ: если оно заполнено меньше чем на 70% - делаете группу ""Underutilized", если на 70-90% - группу "Normal", а если больше 90% - "Overutilized". И далее при построении отчетов в Veeam Reporter или мониторинге с помощью Veeam Monitor вы будете оперативно видеть определенные вами группы хранилищ по категориям. При этом все эти категории будут обновляться автоматически при добавлении, удалении или изменении объектов виртуальной инфраструктуры. То есть работает это в стиле "Set and Forget".
Кроме того, в Veeam Business View 2.0 появился расширенный Dashboard, на котором видно, сколько объектов виртуальной инфарструктуры VMware vSphere уже категоризованы. То есть это обзор вашей инфраструктуры с высоты "птичьего полета".
Ну и по-сути, что еще появилось в Veeam Business View 2.0:
Новые правила определения категорий: не только по географическому принципу или по именам объектов, но и по их свойствам - например, процессоры хост-серверов в мегагерцах.
Исключения для объектов при категоризации (например, вы не хотите чтобы тестовые машины появлялись в представлениях).
Интеграция со сторонними приложениями, например, со службой каталога Microsoft Active Directory, куда можно отобразить изменения, сделанные в Veeam Business View 2.0.
Скачать аддон Veeam Business View 2.0 для своих продуктов Veeam можно по этой ссылке. Документация вот тут.
Таги: Veeam, Business View, Update, vSphere, ESX, Monitor, Reporter, Backup
Угрозы информационной безопасности не исчезнут никогда. По мере расширения арсенала средств бизнес-коммуникаций предотвращать утечки данных становится все сложнее. Внешние атаки становятся все более изощренными, и число их неуклонно растет. Таги:
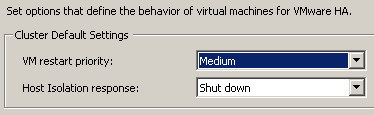
Как вы знаете, в механизме высокой доступности VMware High Availability (HA) есть такая настройка как Isolation Responce, которая определяет, какое событие следует выполнить хосту VMware ESX / ESXi в случае наступления события изоляции для него в кластере (когда он не получает сигналов доступности - Heartbeats - от других хост-серверов).
Leave powered on
Power off
Shutdown
Сделано это для того, чтобы вы могли выбрать наиболее вероятное событие в вашей инфраструктуре:
Если наиболее вероятно что хост ESX отвалится от общей сети, но сохранит коммуникацию с системой хранения, то лучше выставить Power off или Shutdown, чтобы он мог погасить виртуальную машину, а остальные хосты перезапустили бы его машину с общего хранилища после очистки локов на томе VMFS или NFS (вот кстати, что происходит при отваливании хранища).
Если вы думаете, что наиболее вероятно, что выйдет из строя сеть сигналов доступности (например, в ней нет избыточности), а сеть виртуальных машин будет функционировать правильно (там несколько адаптеров) - ставьте Leave powered on.
Но есть еще один момент. Как вам известно, VMware HA тесно интегрирована с технологией VMware Fault Tolerance (непрерывная доступность ВМ, даже в случае выхода физического сервера из строя). Суть интеграции такова - если хост с основной виртуальной машиной выходит из строя, то резервный хост выводит работающую резервную ВМ на себе "из тени" (она становится основной), а VMware HA презапускает копию этой машины на одном из оставшихся хостов, которая становится резервной.
Так вот настройка Isolation Responce не применяется к машинам, защищенным с помощью Fault Tolearance. То есть, если хост VMware ESX с такой машиной становится изолированным, при настройке Power off или Shutdown он такую машину не гасит, а всегда оставляет включенной.
Рекомендация - иметь network redundancy для сети heartbeats. Не должен хост себя чувствовать изолированным, если он весь не сломался.
Копировать руками машину каждый раз, когда нужно внедрить какое-то оборудование, или просто для сохранения данных, это безумно неудобно. Вот для этого и была придумана технология автоматизированного бэкапа, написанная энтузиастами на скриптах perl: ghettoVCB.
Как вы знаете в последнем релизе платформы виртуализации VMware vSphere 4.1 было заявлено множество новых возможностей. Одна из них весьма важна с точки зрения производительности в части работы виртуальных машин с системой хранения. Эта технология называется VMware vSphere VAAI, то есть vStorage API for Array Integration.
Итак, что такое VMware vSphere VAAI. Это комплекс технологий компании VMware, разработанный в сотрудничестве с производителями дисковых массивов (потому и API), предназначенный для передачи некоторых операций виртуальных машин по работе с дисками на сторону массива. В этом случае хост-сервер виртуализации VMware ESX / ESXi при выполнении стандартных процедур в среде виртуализации при работе ВМ с дисковой подсистемой просто дает команду массиву (или массивам) сделать определенные действия, при этом сам хост не гонит через себя все те данные и команды, которые он раньше был вынужден прогонять. То есть, это - Hardware Offloading операций с СХД.
Ну а раз это аппаратно-зависимая вещь, то это означает, что сам массив должен в своем Firmware поддерживать vSphere VAAI (у которой еще бывает несколько видов - так называемые "примитивы"). Чтобы узнать поддерживает ли ваш хост VAAI нужно пойти в VMware Hardware Compatibility Guide и поискать свой дисковый массив в категории "Storage/SAN". Там все сделано несколько криво, но нужно искать в Supported Releases следующую сноску:
VAAI primitives "Full Copy", "Block Zeroing" and "Hardware Assisted Locking" are supported with vmw_vaaip_xxx plug-in
xxx - это идентификатор плагина от VMware
Ну и, конечно, ваш хост VMware ESX / ESXi должен быть версии 4.1 или выше. И помните, что на некоторых массивах VAAI по умолчанию выключена, поэтому вам нужно почитать документацию о том, как ее включить. Кроме того, функциональность VMware vSphere VAAI есть только в изданиях VMware vSphere Enterprise и Enterprise Plus (см. сравнение изданий).
Теперь, какие примитивы (то есть типовые операции с СХД) реализует VMware vSphere VAAI:
Full Copy / Clone Blocks / XCOPY – функция, позволяющая передать на сторону массива возможности копирования объектов виртуальной инфраструктуры без задействования операций четния-записи со стороны сервера VMware ESX 4.1. Эту функцию также называют Hardware Offloaded Copy и SAN Data Copy Offloading.
Write Same / Zero Blocks – возможность обнуления больших массивов блоков на дисковых устройствах для быстрого создания дисков vmdk типа eager zero thick.
Atomic Test and Set (ATS) –возможность защиты метаданных тома VMFS как кластерной файловой системы в ситуациях, когда большое количество хостов ESX имеют разделяемый доступ к одному хранилищу. Также эта функция называется Hardware Assisted Locking.
Давайте рассмотрим как эти компоненты VAAI работают и для чего они нужны.
Full Copy
Используя этот примитив, дисковый массив по команде VMware vSphere осуществляет копирование виртуальной машины (а самое главное для нас копирование диска VMDK) без участия сервера ESX / ESXi и его стека работы с подсистемой хранения (соответственно, не гоняется трафик и не дается нагрузка на CPU). В этом случае гипервизор рассказывает хранилищу, какие блоки занимает виртуальная машина, а оно уже делает все остальное по копированию блоков.
Виртуальная машина может копироваться как в пределах одного хранилища, так и между двумя массивами, если они поддерживают функциональность XCopy. Наиболее интересный способ применения данной техники - это массовое развертывание виртуальных машин из шаблонов, которое больше всего востребовано в VDI-инсталляциях (например, в решении для виртуализации корпоративных ПК предприятия VMware View 4.5).
Еще один важный аспект применения - операция Storage vMotion, которая требует копирования виртуальных дисков машины.
С vSphere VAAI операции по копированию блоков данных хранилищ виртуальных машин занимают меньше времени (в некоторых случаях оно сокращается на 95%):
Ну а вот такие результаты нам выдает Storage vMotion:
Кроме того, данная технология интегрирована и с функциональностью "тонких" (thin) дисков как самой VMware, так и механизмом Thin Provisioning сторонних вендоров.
Write Same / Zero Blocks
За счет этой технологии сервер VMware ESX / ESXi может дать команду хранилищу обнулить блоки виртуальных дисков типа Eager zeroed thick (см. типы дисков). Эти диски являются самыми безопасными (блоки чистятся при создании) и самыми производительными (при обращении к блоку его не надо обнулять и тратить ресурсы), но занимали очень много времени на их создание. Теперь с техникой VAAI этот процесс сильно ускоряется, что позволяет использовать диски eagerzeroedthick чаще (например, для машин с включенной Fault Tolerance). Напомню, что сейчас по умолчанию в VMware vSphere создаются диски типа Zeroed thick disks.
Теперь одинаковые команды ввода-вывода на сторадж от сервера ESX / ESXi дедуплицируются, а массиву дается команда на повторение одинаковых команд для разных блоков. На эту тему есть отдельное видео:
Atomic Test and Set (ATS) или Hardware Assisted Locking
За счет этой техники vSphere VAAI существенно уменьшается число операций с хранилищем, связанных с блокировкой LUN на системе хранения. Как вы знаете, при работае виртуальных машин возникают конфликты SCSI Reservations, связанные с тем, что некоторые операции вызывают блокировку всего LUN для обновления метаданных тома VMFS. Операций этих много: запуск виртуальной машины (обновляется lock и создаются файлы), развертывание новой ВМ, создание снапшота, миграция vMotion и т.п.
Нехорошо также, что при использовании тонких дисков (например для связанных клонов VMware View) также происходит блокировка LUN при выделении нового блока растущему диску (надо обновлять метаданные - см. тут). Это, прежде всего, приводит к тому, что возникает ограничение на количество размещаемых на LUN виртуальных машин, чтобы конфликтов SCSI Reservations не было слишком много.
Теперь же, за счет VAAI, эти операции передаются на сторону дискового массива, который при необходимости обновить метаданные тома не блокирует весь LUN, а лочит только секторы метаданных, которые требуется обновить. Все это делается массивом безопасно и надежно. Отсюда вытекает уменьшение числа конфликтов SCSI Reservations и ,как следствие, лучшая производительность и увеличения числа ВМ на LUN.
Ограничения VMware vSphere VAAI
Недавно мы писали про Data Mover'ы - это компоненты VMware ESX / ESXi, отвечающие за работу хост-сервера с хранилищами при копировании данных. Поддержкой VAAI заведует компонент fs3dm – hardware offload. Он пока еще молодой, поэтому не поддерживает некоторых сценариев использования. Соответственно все или некоторые техники VAAI у вас не будут работать в следующих случаях:
Исходный и целевой тома VMFST имеют разные размеры блоков
Исходный файл лежит на том RDM, а целевое хранилище - это не том RDM
Исходный тип диска VMDK - это eagerzeroedthick, а целевой - thin
Исходный или целевой тип диска VMDK VMDK - один из типов sparse или hosted (не платформа vSphere)
Исходная виртуальная машина имеет снапшот
Блоки хранилища, где лежит виртуальная машина не выровнены (по умолчанию vSphere Client выравнивает блоки автоматически)
Как включить VMware vSphere VAAI
Как уже было сказано выше, со стороны хранилищ VAAI может быть выключена и нужно почитать документацию на СХД. На хостах ESX / ESXi по умолчанию VAAI включена. Проверить это можно, перейдя в Configuration > Advanced Settings и увидев следующие параметры, напротив которых стоят единицы:
DataMover/HardwareAcceleratedMove (это возможности Full Copy)
DataMover/HardwareAcceleratedInit (это Zero Block)
Если ваше хранилище не поддерживает VAAI - ничего страшного, хост ESX / ESXi будет работать софтовыми дедовскими методами.
Как проверить, работает ли vSphere VAAI?
Очень просто, откройте категорию Storage на вкладке Configuration в vSphere Client и посмотрите в последний столбик.
Статус Unknown означает, что хост еще не обращался к операциям, которые поддерживаются VAAI (то есть, это дефолтный статус). Если вы сделаете какую-нибудь операцию с VAAI (например, Copy/Paste виртуального диска больше 4 МБ), то VAAI попробует отработать. Если он отработает успешно - выставится статус Supported, ну а если нет - то Not Supported.
Опросить стораджи можно также из командной строки:
23 февраля 2011, Орландо, США. Компания Parallels, мировой лидер в сфере ПО для облачных вычислений и виртуализации настольных компьютеров, объявляет об утверждении президента компании Биргера Стена в должности генерального директора. Таги:
Как мы уже писали, в VMware vSphere 4.1 появилась технолония Storage IO Control (SIOC, подробности здесь), которая позволяет настраивать приоритеты доступа виртуальных машин к хранилищам не в рамках одного хоста VMware ESX / ESXi, а в рамках всего кластера.
и какие рекомендации по настройкам Latency можно использовать при борьбе виртуальных машин за ресурсы ввода-вывода, в зависимости от типов хранилищ:
Второй документ называется "Managing Performance Variance of Applications Using Storage I/O Control". Он содержит результаты тестирования SIOC в условиях, когда нужно выделить виртуальную машину как критичную с точки зрения ввода-вывода (отмечена звездочкой). Взяли требовательную к нагрузкам задачу (DVD Store).
Измерили эталонную производительность когда работает только критичная ВМ (левый столбик - принят за единицу, SIOC Off), измерили среднуюю производительность (когда все машины работают параллельно и у каждой Shares установлено в 1000, SIOC Off), а потом стали варьировать Shares для критичной виртуальной машины (при включении SIOC On) смотря на то, как растет ее производительность в рамках кластера:
Видим, что SIOC при распределении приоритета ввода-вывода между хостами работает. В этом же документе есть еще тесты, посмотрите.
Как вы знаете, для виртуальных хранилищ (datastores) в VMware vSphere есть возможность задавать разные размеры блоков тома VMFS. Также вы, вероятно, знаете, что операция Storage vMotion позволяет перемещать виртуальную машину между хранилищами, превращая ее виртуальный диск из толстого (thick) в тонкий (thin).
Но чтобы это результирующий тонкий диск после Storage vMotion занимал на целевом хранилище только столько пространства, сколько используется внутри гостевой ОС (а не весь заданный при создании), нужно предварительно почистить блоки с помощью, например, утилиты sdelete.
Duncan Epping, известный технический эксперт VMware, обратил внимание на проблему, когда пользователь делает очистку блоков, затем Storage vMotion, а уменьшения диска не происходит. Почему так?
Очень просто, в составе VMware ESX / ESXi есть три типа datamover'ов ("перемещателей"):
fsdm – это старый datamover, который представляет собой базовую версию компонента. Он работает сквозь все уровни, обозначенные на картинке. Зато он, как всегда, универсален.
fs3dm – этот datamover появился в vSphere 4.0 и имеет множество оптимизаций. И вот тут данные уже не идут через стек работы с виртуальной машиной. То есть он работает быстрее.
fs3dm – hardware offload – Этот компонент появился для поддержки технологии VAAI, которая позволяет вынести операции по работе с хранилищами виртуальных машин на сторону массива (hardware offload). Он, естественно, самый быстрый и не создает нагрузку на хост VMware ESX / ESXi.
Так вот основная мысль такова. Когда вы делаете миграцию Storage vMotion виртуальной машины между хранилищами с разными размерами блоков используется старый datamover fsdm, а когда с одинаковыми, то новый fs3dm (в программном или аппаратном варианте). Последний работает быстрее, но не умеет вычищать нулевые блоки на целевом хранилище у виртуального диска VMDK.
А вот старый fsdm, ввиду своей универсальности, это делать умеет. То есть, если нужно вычистить нулевые блоки не перемещайте ВМ между хранилищами с одинаковыми размерами блоков. Так-то вот.
Как вы знаете, у компании Veeam есть замечательный продукт Veeam Backup and Replication 5, который умеет делать не только резервные копии и восстановление виртуальных машин, но и репликацию, и виртуальные тестовые лаборатории, и напрямую может запускать ВМ из резервных копий. А сегодня мы посмотрим еще на один модуль - Veeam Search Server, тем более, что поставить его не так просто.
Таги: Veeam, Backup, Search, VMware, vSphere, Storage, Обучение
Компания StarWind Software выпускает обновленную версию продукта StarWind iSCSI SAN, имеющую новые возможности по дедупликации хранилищ (экспериментально) и улучшения в интерфейсе, позволяющие упростить обслуживание хранилищ для виртуальных машин и уменьшить необходимое время на администрирование инфраструктуры хранения данных. Таги:
Как вы знаете, начиная с VMware vSphere 4.1, компания VMware включила с свою платформу виртуализации API для обеспечения безопасности виртуальных сред под названием EPSec (End Point Security). Совместно с технологией VMware VMsafe этот API должен позволить по-новому обеспечивать антивирусную защиту в виртуальных машинах на VMware ESX / ESXi (см. нашу запись о Trend Micro и Reflex VMC).
Сейчас традиционные антивирусы работают в виртуальных машинах, создавая нагрузку на них. Для виртуальных серверов это не так важно, поскольку их плотность на хост-машинах достаточно невелика. Да и потом, современнные антивирусы типа Symantec или Trend Micro имеют имеют функции случайного запуска, чтобы равномерно распределить нагрузку. Но для виртуальных ПК (например, на базе VMware View) коэффициент консолидации может достигать 50 и даже 100 к одному - и вот тут нужно искать пути оптимизации использования аппаратных ресурсов.
И здесь на помощь приходит VMware VMsafe и EPSec API:
Суть технологии такова - зачем использовать отдельный антивирус в каждой виртуальной машине, если можно сделать сервисную виртуальную машину, содержащую в себе средства сканирования активности виртуальных машин на уровне гипервизора, и тратить ресурсы только на нее. Естественно этот виртуальный модуль (Virtual Appliance) имеет все необходимое для поддержки перемещаемых средствами vMotion/DRS машин.
У компании Trend Micro уже есть продукт DeepSecurity 7.5, который поддерживает эту интересную технологию (Symantec и McAfee тоже скоро подтянутся). VMsafe-net API отвечает за единый фаервол, а EPsec API - за антивирусную деятельность.
Недавно Tolly group сделала его бенчмаркинг, показатели которого были впечатляющими: использование данной технологии позволяет сократить потребление ресурсов от 1.7 до 8.5 раза!
Кстати реализует упомянутые технологии продукт vShield Endpoint, входящий в состав VMware View Premier, о котором мы уже писали:
Часто разговаривая с заказчиками и пользователями платформ виртуализации от VMware, я вижу, что у многих из них весьма широко применяются снапшоты (snapshots), в том числе для целей "резервного копирования". Эти снапшоты живут долго, их файлы разрастаются и поростают плесенью. Потом инфраструктура начинает тормозить, а пользователи не знают почему. И как это не казалось бы странным - удаление всех снапшотов у всех виртуальных машин решает их проблемы, с которыми они уже свыклись.
Сегодня я вам расскажу, чтоб вы наконец запомнили: снапшоты это в целом плохо и лишь иногда хорошо. На эту страницу мы с вами будем отсылать наших клиентов и пользователей виртуальных машин, которыми могут оказаться люди, не участвующие в процессе администрирования VMware vSphere, но пользующиеся функционалом снапшотов (например, веб-разработчики).
Начнем с того, когда снапшоты могут помочь (я имею в виду, конечно, руками делаемые снапшоты, а не автоматические, которые делает, например, Veeam Backup). Снапшоты в VMware vSphere оказываются полезны в очень ограниченных условиях (например, для проверки корректности работы обновления приложения или патча операционной системы). То есть эта та точка сохранения состояния виртуальной машины, к которой можно будет вернуться через небольшой промежуток времени. Ни в коем случае нельзя рассматривать снапшоты как альтернативу резервному копированию основных производственных систем, в силу множества проблем, о которых пойдет речь ниже.
Что плохого в снапшотах виртуальных машин на VMware ESX:
1. Снапшоты неконтролируемо растут (блоками по 16 МБ). Помимо базового диска ВМ фиксированной емкости вы имеете еще один файл отличий виртуального диска, который растет как ему вздумается (предел роста одного снапшота - размер базового диска). Особенно быстро растут снапшоты для ВМ с приложениями с большим количеством транзакций (например, почтовый сервер или сервер СУБД). Со снапшотами вы не имеете контроля над заполненностью хранилищ.
2. Большое количество снапшотов (особенно цепочки, в которых может быть до 32 штук) вызывает тормоза виртуальной машины и хост-сервера ESX (в основном замедляется работа с хранилищем). Проверено на практике. Даже VMware пишет так: "An excessive number of snapshots in a chain or snapshots large in size may cause decreased virtual machine and host performance". В качестве примера можно привести тот факт, что при аллокации блоков снапшота происходит блокировка LUN (в этом режиме он доступен только одному хосту, остальные ждут). Когда снапшот делается - машина подвисает из-за сброса памяти на диск.
3. Снапшоты не поддерживают многие технологии VMware, созданные для автоматизации датацентров. К ним относятся VMware Fault Tolerance, Storage VMotion и другие. Когда одни машинки в чем-то участвуют, а другие не участвуют - это нехорошо в рамках концепции динамической инфраструктуры.
4. Снапшоты вызывают специфические проблемы при операциях с ВМ. Например, расширение диска виртуальной машины со снапшотом приводит к потере данных и непонятками, что дальше с такой машиной делать. Сто раз уже пользователи влипали (вот как вытянуть себя за волосы). Интересно также восстановить из снапшота машину с IP-адресом, который на данный момент уже используется в сети.
5. Со снапшотами бываютбаги, а бывает, что они просто "by design" тупят.
1. Контролируйте наличие снапшотов у виртуальных машин и их размеры, своевременно удаляйте их совместно с владельцами систем. Делать это можно, например, с помощью RVTools.
2. Не храните снапшоты больше 24-72 часов. Этого времени достаточно, чтобы оттестировать обновление ПО или патч ОС (ну и, конечно, сделать бэкап).
3. На сервере VMware vCenter можно настроить алармы на снапшоты виртуальных машин. Сделайте это. Дрючьте пользователей за необоснованные снапшоты.
4. Не позволяйте делать больше 2-3 снапшотов для виртуальной машины в принципе, если это делается в производственной среде. На своих выделенных для тестирования ресурсах (изолированных) пусть разработчики делают что хотят.
5. Если вы используете ПО для резервного копирования через снапшоты ВМ (например, Veeam Backup), помните, что бывает некоторые невидимые в vSphere Client снапшоты (Helpers) остаются на хранилище. Поглядывайте за машинами из командной строки.
Если вы используете пулы типа Linked Clone (на основе базового образа) в решении для виртуализации ПК VMware View 4.5, то знаете, что есть такая операция "Rebalance", которая перераспределяет виртуальные ПК пула по хранилищам VMFS / NFS. Но многие удивятся, как работает эта функция. Например, у вас есть несколько хранилищ различной емкости, и вы делаете Rebalance десктопов.
Получаете вот такую картину:
Слева - то, что вы ожидаете увидеть в результате балансировки, а справа - то, что получается на самом деле. В чем причина?
Все дело в том, что VMware View 4.5 использует для перемещения машин на хранилище параметр "weighted available space". У какого из хранилищ он больше - туда виртуальные машины и переезжают. Что это за параметр:
datastore_capacity - это общая емкость хранилища VMFS / NFS.
virtual_usage - это максимально возможный объем, занимаемый виртуальными машинами на хранилище, который формируется из размера виртуальных дисков машин (номинального, а не реального) + размер памяти (для Suspend).
overcommit_factor - это настройка для Storage Overcommit, которую вы задавали для Datastore, когда выбирали, какие из них следует использовать для пулов Linked Clone. Там были такие значения:
None - хранилище не является overcommitted.
Default - это коэффициент 4 от размера хранилища
Moderate - это коэффициент 7 от размера хранилища
Aggressive - это коэффициент 15 от размера хранилища.
Если вы забыли, где это выставляли, то это вот тут:
Теперь переходим к примеру и формуле. Есть у нас вот такая картинка (см. настройки overcommitment):
Теперь вот вам задачка - что будет в результате Rebalance виртуальных ПК?
По-сути, правило таково: если у вас все хранилища с одинаковым уровнем Storage Overcommitment и одинакового размера, то виртуальные машины будут перемещены на другие хранилища, если там больше свободного места, чем свободного места на текущем хранилище. Ну а если разного размера и одинакового уровня Overcommitment - то ожидайте того, что машины останутся на больших хранилищах. Так-то вот.
И да, никогда не далейте Storage VMotion для виртуальных машин VMware View 4.5 вручную - это не поддерживается со стороны VMware.
Как мы уже писали, в декабре прошлого года вышел релиз-кандидат продукта Veeam nworks Smart Plug-in 5.6, который позволяет организовать ээфективный мониторинг и решение проблем для виртуальной инфраструктуры VMware vSphere. Многие компании уже приобрели решения Microsoft System Center Operations Manager (SCOM) и HP Operations Manager (HP OM), необходимые для мониторинга физической инфраструктуры, так вот Veeam с помощью семейства продуктов nworks позволяет прикрутить к этим продуктам еще и мониторинг инфраструктуры виртуализации VMware. На днях параллельно вышли новые версии обоих продуктов - Veeam nworks Smart Plug-In 5.6 и Veeam nworks Management Pack 5.6.
Veeam nworks Smart Plug-In 5.6 для HP OM теперь имеет следующие новые возможности:
Поддержка HP Operations Manager для Linux (OML). Теперь портфель nworks включает в себя поддержку всех версий HP OM - для Windows, Unix и Linux.
Обновленный Enterprise Manager, доступный из консоли Ops Manager, который можно прикрутить как плагин к vSphere Client.
Ограничение очереди событий vCenter. Это позволя определить число событий vCenter, которые коллектор может получать в течении 30 секунд.
Новые метрики и события, отслеживания некоторых из которых вы больше нигде не найдете:
Отслеживание задержек обращения к хранилищам (Disk queue latency) - для определения узких мест в дисковой подсистеме хранения виртуальных машин на томах VMFS
Производительность сетевого взаимодействия
Мониторинг длительности хранения снапшотов (snapshots) - для нотификации администраторов о потенциальных проблемах
Сигнал с датчика вентилятора
Новые события, появившиеся в vSphere 4.
Message Forwarding - теперь сообщения любых типов могут быть разбиты по группам и помещены в соответствующие узлы консоли Operations Manager.
Улучшенная производительность коллектора и самодиагностики.
Veeam nworks Management Pack 5.6 для Microsoft SCOM теперь имеет следующие новые возможности:
Новые метрики VMware vSphere 4.1:
Memory compression (см. выше)
Disk queue latency (см. выше)
Потеря пакетов в сетевом взаимодействии
Мониторинг длительности хранения снапшотов (см. выше)
Новые события vSphere 4
Улучшенная масштабируемость:
Улучшенная производительность при обнаружении хостов с большой плотностью виртуальных машин (например, при VDI-инсталляции в рамках VMware View 4.5)
Улучшенная производительность мониторинга состояния оборудования
Интеллектуальная группировка виртуальных машин, позволяющая не запутаться в окружениях, где машины постоянно перемещаются с хоста на хост (например, DRS/VMotion)
Ограничение очереди событий vCenter. Это позволя определить число событий vCenter, которые коллектор может получать в течении 30 секунд.
Сигнал с датчика вентилятора
Напоминаю, что оба данных продукта являются частью решения Veeam ONE, которое позволяет осуществлять комплексный мониторинг инфраструктуры виртуальных серверов VMware vSphere, а также получать отчетность о конфигурациях и отслеживать происходящие в виртуальной среде изменения и управлять ими.
Скачать Veeam nworks Management Pack 5.6 можно тут, а Veeam nworks Smart Plug-In 5.6 тут.
Кстати, еще одна тема. Недавно компания Veeam получила аж 4 награды от Virtualization Review и SearchServerVirtualization.com:
Как вы знаете, у компании VMware есть несколько инициатив в сфере облачных вычислений - это семейство технологий vCloud, продукт vCloud Director для создания субоблаков и управления ими, надстройка vCloud Request Manager (портал самообслуживания пользователей облачных виртуальных машин + управление жизненным циклом ВМ) и ветка vCloud Express для создания облачной виртуальной инфраструктуры на площадках провайдеров, предоставляющих в аренду виртуальные машины. Сюда нужно присовокупить еще продукт VMware vCenter Chargeback, который обсчитывает все аспекты затрат на виртуальную инфраструктуру, и множество других продуктов семейства vCenter. Плюс вспомогательные продукты семейства vShield.
Теперь вот появилась новая инициатива - VMware vCloud Connector. По-сути, это механизм соединения облачных инфраструктрур на базе VMware vSphere (но не только).
На практике это будет означать вот что: VMware vCloud Connector - это будет абсолютно бесплатный плагин к VMware vCenter, с помощью которого пользователь своей частной виртуальной инфраструктуры может перемещать свои виртуальные машины в облако, т.е. к провайдеру, который дает виртуальную инфраструктуру в аренду. Происходит это, в том числе, с использованием VMware vCloud API.
При этом виртуальные машины по-прежнему остаются под контролем своего vCenter в vSphere Client:
Кроме того, в составе VMware vCloud Connector будет идти виртуальный модуль (Virtual Appliance), который вы импортируете в свою инфраструктуру VMware vSphere.
Поначалу VMware vCloud Connector, который выйдет уже в конце этого квартала будет поддерживать только двух провайдеров US Bluelock и European Colt, но потом эта инициатива дойдет и до нас.
Почему такая возможность будет полезна вам? Да потому, что у провайдеров облако, а у вас не облако. Облако - это не просто установленная vSphere, но и много чего еще. Например:
Контроль и мониторинг ресурсов
Классы сервиса для групп приложений и отдельных клиентов в целом (SLA) с ответственностью за простой
Контроль жизненного цикла виртуальных машин
Прозрачная система расчета стоимости ресурсов
Централизованное обеспечение безопасности на уровне датацентра
Фишка в том, что VMware vCloud Connector - это всего лишь начало большой инициативы, о которой станет известно чуть позже. Там будут и сторонние гипервизоры, и федерация гибридных облаков, и много чего еще. Не волнуйтесь - скоро обо всем расскажем. Напоследок картинка:
Пало-Альто, Калифорния, США. - Компания VMware (NYSE: VMW), мировой лидер в области виртуализации и облачных вычислений, объявила о доступности VMware Go Pro, полнофункционального облачного сервиса, который позволит малому и среднему бизнесу (СМБ) консолидировать, контролировать и защищать физическую и виртуальную IT-инфраструктуру. Таги:
В конце 2010 года фирма Intel сообщила о своем желании приобрести одного из ведущих поставщиков антивирусных решений — McAfee. На первый взгляд, — несуразное решение, но только на первый. Встраивание механизмов защиты от вирусов непосредственно в аппаратуру компьютера — это многообещающая идея и новая ступень в развитии антивирусных технологий.
Таги: VMachines, Hardware, Security, Intel, McAfee, Red Pill,
Пало-Альто, Калифорния, США. – Компания VMware, мировой лидер в области виртуализации и облачных вычислений, обнародовала финансовые результаты четвертого квартала и всего 2010 года.
Доход компании в четвертом квартале составил 836 миллионов долларов США, что на 37% превышает результаты аналогичного периода 2009 года. Таги:
Пало-Альто, Калифорния, США. – Компания VMware, мировой лидер в области виртуализации и облачных вычислений, обнародовала финансовые результаты четвертого квартала и всего 2010 года.
Доход компании в четвертом квартале составил 836 миллионов долларов США, что на 37% превышает результаты аналогичного периода 2009 года. Таги:
Сейчас модно иметь всякие смартфоны, айфоны и прочие фоны. Между тем, есть несколько приложений, которые могут помочь вам в работе и просто не скучать, написанных под задачи, связанные с виртуализацией. Вот, кое-что интересное:
Это приложение от самой VMware. С помощью него можно читать VMware Knowledge Base, можно смотреть VMware KB TV, а также смотреть что пишут интересного о виртуализации в твиттере:
Поддерживается не только Айфон, но и Android-девайсы.
Хотите рулить виртуальной инфраструктурой VMware vSphere прямо с вашего iPhone? Пожалуйста, есть такая программка:
Обратите внимание, как прикольно делать VMotion - крутите барабан! Печально, но нет поддержки ESX 4.0 / 4.1 (но VC 4.0 есть). Ребята работают над этим.
Эта софтинка позволяет открыть рабочий стол вашего компьютера (виртуальной машины в инсталляции VDI под VMware View) на мобильном телефоне. Мелковато, конечно, а куда деваться:
Пока, опять-таки, только VCP-310, но будем надеяться, что и для четверки скоро выйдет тоже. Интересный быстрогайд по подготовке к экзамену на сертификацию VMware Certified Professional.
Одна глава идет бесплатно. Программка от Pearson Education, кстати.
Об этом приложении мы уже писали на vSphere.ru. iDatacenter позволяет агрегировать статистику виртуальной инфраструктуры VMware vSphere на вашем iPad, искать различные объекты, управлять состоянием виртуальных машин, делать Storage vMotion, а также управлять состоянием хостов (питание, Maintenance Mode).
Это спецализированное приложение для смартфонов BlackBerry и iPhone, с помощью которого можно управлять всем на свете (System Center, Nagios, BMC и др.), в том числе VMware Virtual Infrastructure и Microsoft Hyper-V.
Недавно появился также и Android-клиент:
С виртуальными машинами и хостами VMware можно делать не так уж много:
view data centers/hosts/clusters in VMware Infrastructure
view resource pools
edit resource pool settings
find virtual machines
view VM properties
edit VM settings
view events and event details
view tasks and task details
view triggered alarms and triggered alarm details
view host summaries and manage host
С Hyper-V можно делать и того меньше. Странно, но я не нашел в документации, какие версии VMware VI/vSphere и Hyper-V поддерживаются, поэтому если нужно см. документацию.
Таги: VMware, vSphere, Mobile, ESX, iPhone, Apple, iPad, Android, Google
Изменений немного, но я, например, узнал, что с версии vSphere 4.1 операции Copy/Paste для виртуальной машины отключены по дефолту как раз в целях безопасности. Обсуждение документа продлится до конца февраля, а окончательный релиз состоится скорее всего весной.
Таги: VMware, vSphere, Security, Update, ESX, Whitepaper, vCenter, VUM
Хватит товарищи слушать всякую гадость. Все знают, что о вкусах не спорят, но есть то - что вечно и нравится всем, пусть даже свое собственное зашоренное самомнение не дает в этом признаться. Разве эта музыка не будет вечной в часы вашей бесконечной грусти? Ссылок не будет - потрудитесь немного.
Schiller & Peter Heppner - Vielleicht
Frederic Francois Chopin - Spring Waltz
Yuri Kane - Right Back (а для активного прослушивания лучше даже брать Mashup remix с Armin van Buuren)
Telepopmusic - Breath
Andrey Danilko - After you
Craig Armstrong - Featuring Eliz
Flanders - Behind
Adam F ft Tracy Thorn - The Tree Knows Everything
Bebe - Siempre me quedar (почти как Zaz)
Infected Mushroom - Dancing With Kadafi
Kosta Rodrigez ft. Denise - Soul To Sell
Jeter Avio - Tears
ATB - My everything
Kimito Lopez - Selfish By Nature
Tilt feat Maria Nayler - Angry Skies
Pink Floyd - One Slip
Royksopp - Sparks (Special Japanese only live)
Oceanlab - Come Home
Lamb - Angel Gabriel
Krister Linder - Dare
Rolf Lovland - Closer To The Dream
Kim Sanders - I Know
Chrisso - for ann (эффект Шепарда)
Miranda - Vamos a Jugar en el sol (хит парижских дискотек 95-го года! Эта песня лишняя в списке - но весьма для души)
В следующий раз я напишу о том, что энергичным людям создает хорошее настроение.
Компания Citrix продолжает помаленьку выпускать обновления своих продуктов в сфере виртуализации. На днях вышло первое обновление клиентского гипервизора Citrix XenClient 1.0 SP1, который позволяет осуществлять доставку виртуальных машин на клиенские ПК без необходимости установки хостовой ОС (подробнее тут и тут).
Новые возможности Citrix XenClient 1.0 SP1:
Официальная поддержка новых ноутбуков: Lenovo T510 и Panasonic Toughbook 52 в списке совместимости (HCL)
Интеграция с технологией Citrix FlexCast – появилась поддержка потоковой доставки виртуальных дисков VHD через службы развертывания provisioning services
Улучшена поддержка воспроизведение аудио и звукозаписи в виртуальных ПК
Ускоренная загрузка и вход в систему в виртуальных машинах
Больше возможностей и гибкости в настройке сети для XenClientEnhanced network configurations and reliability
Улучшена поддержка интернационализации
Кроме того, внесены улучшения в Citrix Synchronizer (компонент для передачи образов виртуальных машин и их изменений от образа на сервере на клиентское устройство, т.е. синхронизации машины):
Улучшена обработка нестандартных имен хостов
Улучшенная кросс-браузерная совместимость для UI
Повышенная надежность при передаче виртуальной машины
Поддержка offline-кэширования кредов в Active Directory
Побольше информации об использовании дискового пространства
Улучшения безопасности
Не так много для сервис пака, но что есть. Скачать обновленный Citrix XenClient 1.0 SP1 можно по этой ссылке.
Теперь Citrix XenConvert 3.2 - это утилита для миграции физических серверов на платформу виртуализации Citrix XenServer. Но можно также и конвертировать виртуальные машины из форматов VHD, VMDK, OVF и XVA.
Что нового:
Совместимость с Citrix XenServer 5.6 FP1
Совместимость с Provisioning Services 5.6 SP1
Множественные багофиксы ошибок при конферсии физических серверов
1. В конце прошлого года вышел Citrix XenApp 6 Fundamentals. Напомню, что XenApp - это мощное средство виртуализации и доставки приложений пользователям корпоративной инфраструктуры настольных ПК. Fundamentals - это издание для малого бизнеса, объединяющее в себе основные функции XenApp по сходной цене.
2. Также в конце года вышел Citrix Receiver для Chrome OS (вот тут - из блога). Фишка такая - вы логинитесь из какого-нибудь нетбука в консоль Reciever - и получаете свое приложение в отдельной вкладке браузера:
Переключаетесь между вкладками - переключаетесь между приложениями. Все построено на HTML5, поэтому должно работать шустро. Citrix Receiver будет распространяться через магазин веб-приложений Chrome Web Store от Google, который будет запущен в первой половине 2011 года.
Константин Введенский, мой старый приятель и по совместительству сотрудник компании StarWind Software, опубликовал интересные заметки по оптимизации работы хранилищ виртуальных машин VMware ESX на базе продукта StarWind Enterprise. Если кто-нибудь из вас все еще не знает как StarWind может помочь вам в создании отказоустойчивых систем хранения по iSCSI для виртуальных машин серверов VMware ESX, то вам сюда, сюда, и, вообще, сюда.
О чем говорят нам эти заметки:
1. iSCSI Initiator на VMware ESX можно использовать в режиме NIC binding (то есть Teaming в настройках vSwitch), или в режиме MPIO (multipathing, в настройках политики путей к хранилищу в категории Storage), но нельзя их использовать одновременно. Еще посмотрите сюда.
2. Если вы используете и хранилища NAS/NFS, и хранилища iSCSI, то нужно использовать NIC Teaming для обоих интерфейсов, а не MPIO.
3. Для типа балансировки IP Hash вы сможете использовать только 1 iSCSI-соединение на хост VMware ESX. Как настраивается тип балансировки IP Hash изложено в KB 100737.
4. По умолчанию время выбора пути в случае отказа на VMware ESX равно 300 секунд. Это время рекомендованное VMware. Вы можете уменьшить или увеличить это время. Его уменьшение ускорит переключение на резерв, но даст нагрузку на процессор ESX (более частый опрос путей), увеличение этого времени снизит нагрузку на CPU, но и увеличит время Failover'а. Настраивается этот параметр в Advanced Settings сервера ESX - он называется Disk.PathEvalTime, и его значение может варьироваться в диапазоне от 30 до 1500. Более подробно в VMware KB 1004378 и еще вот тут посмотрите, например.
5. В виртуальных машинах Windows убедитесь, что параметр Disk\TimeOutValue в реестре равен 60 секундам. Это позволит дисковому устройству не отваливаться раньше времени. Если VMware Tools установлены, то он будет равен 60 секундам после установки, если же нет, то это будет 10 секунд (non-cluster) или 20 секунд (cluster node). Настраивается он вот в этом ключе реестра:
Для Linux все немного не так. Без VMware Tools время TimeOutValue равно 60 секундам, а с ними - 180 секундам. Настраивается TimeOutValue в Linux так:
cat /sys/block/<disk>/device/timeout
Для большинства случаев подойдет значение в 60 секунд.
6. Для достижения лучшей производительности со StarWind Enterprise лучше использовать политику балансировки нагрузки по нескольким путям Round Robin (не активирована по умолчанию, по дефолту стоит политика Fixed). Для этого нужно щелкнуть правой клавишей по устройству iSCSI и нажать "Manage Paths" в vSphere Client.
Эта политика позволяет переключаться между путями каждые 1000 IOPS'ов. Можно уменьшить это значение для оптимизации производительности. Для этого в сервисной консоли ESX / ESXi наберите:
В данном случае выставлено 3 IOPS'а. UUID девайса можно узнать в категории "Storage adapters" в vSphere Client для сервера ESX. Опросить текущие настройки устройства можно командой сервисной консоли:
esxcli nmp roundrobin getconfig --device [UUID]
Ну и, конечно, помните, что все эти настройки нужно сначала опробовать в тестовой среде и посмотреть на изменения в производительности работы сервера ESX с хранилищем StarWind Enterprise.
Скачать StarWind Enterprise HA можно по этой ссылке, ну а покупают его только здесь.
Как обычно, Duncan Epping написал отличный пост об использовании памяти виртуальными машинами на хостах VMware ESX. Постараемся объяснить это на русском языке. Итак, если открыть вкладку Summary в vSphere Client для виртуальной машины, мы увидим вот такую картину:
Здесь есть 2 главных параметра:
Memory - это то количество оперативной памяти, которое вы выделили виртуальной машине при создании. За это количество гостевая ОС не выйдет при ее использовании. Это же количество памяти вы увидите в гостевой ОС.
Memory Overhead - это количество памяти, которое может потребоваться гипервизору на поддержание работы виртуальной машины сверх используемой памяти (т.е. расчетные накладные расходы на виртуализацию, но не текущие).
Далее мы видим панель Resources, здесь есть такие показатели:
Consumed Host Memory - это количество физической памяти хоста ESX, выделенной виртуальной машине. Обычно это значение не больше значения Memory на предыдущей картинке. Но может быть и больше, поскольку Consumed Host Memory включает в себя и Memory Overhead, но не с картинки выше, а реально используемый гипервизором Overhead (о котором будет идти речь ниже). И важный момент - счетчик Consumed для Memory на вкладке "Performance" не включает в себя Overhead.
Active Guest Memory - это количество памяти, которое по мнению гипервизора VMkernel активно используется гостевой операционной системой. Вычисляется этот параметр на базе статистических показателей. То есть, если ОС не очень активно использует память, то можно ей ее немного подрезать в условиях нехватки ресурсов.
Теперь идем на вкладку "Resource Allocation". Здесь все немного сложнее:
Появляются вот такие показатели:
Для Host Memory (видим, что это 2187 МБ = сконфигурированная память 2048 МБ + Overhead):
Consumed - это, опять-таки, объем потребляемой виртуальной машиной физической памяти хоста ESX (постоянно меняется). И он включает в себя накладные расходы гипервизора по памяти.
Overhead Consumption - это текущий объем затрат памяти на поддержание виртуальной машины (здесь 42 МБ в отличие от расчетного в 110 МБ)
А формула такова: Consumed = Private + Overhead Comsumption
Для Guest Memory (2048 МБ сконфигурировано в настройках):
Private - это объем памяти физически хранимый хостом для виртуальной машины (см. формулу выше).
Shared - это объем памяти, который отдается другим виртуальным машинам от разницы между сконфигурированным объемом (Configured Memory) и потребляемым (Consumed). Суть в том, что ОС Windows при загрузке очищает всю память виртуальной машины, но потом эти пустые страницы приложениями не используются. Поэтому гипервизор отдает их другим ВМ, пока ВМ, владеющая памятью не потребует их. Эти страницы и есть Shared. Как мы видим, Private + Shared = Guest Memory.
Swapped - это объем памяти, ушедший в файл подкачки vswp. То есть это не файл подкачки Windows, а файл подкачки в папке с виртуальной машиной. Само собой этот показатель должен быть нулевым или совсем небольшим, поскольку своппинг, который делает ESX (а точнее VMkernel) - это плохо, т.к. он не знает (в отличие от Windows), какие страницы нужно складывать в своп, поэтому кладет все подряд.
Compressed - это объем памяти, который получен после сжатия страниц с помощью механизма Memory Compression (то есть, хранимый в VM Compression Cache).
Ballooned - это объем памяти, который забрал balloon-драйвер (vmmemctl), чтобы отдать ее другим нуждающимся виртуальным машинам.
Unaccessed - это память, к которой гостевая ОС ни разу не обращалась (у Windows - это близко к нулю, так как она обнуляет память при загрузке, у Linux должно быть как-то иначе).
Active - опять-таки, активно используемая память на основе статистики гипервизора.
На хорошем и производительном хосте VMware ESX метрики Compressed, Ballooned, Unaccessed - должны быть около нуля, так как это означает что машины не борются за ресурсы (то есть не сжимают страницы и не перераспределяют память между собой). Ну и, конечно, если показатель Active маленький, стоит задуматься об урезании памяти (но сначала посмотрите в гостевую ОС, она лучше знает, чем гипервизор, все-таки).
Worst Case Allocation - это сколько будет выделено виртуальной машине при самом плохом раскладе (максимальное использование ресурсов), то есть вся память будет использоваться, да еще и накладные расходы будут (т.е., Configured + максимальный Overhead).
Overhead Reservation - это сколько зарезервировано памяти под Overhead гипервизором.

 RSS
RSS